Gemini API (gemini-2.0-flash-001 multimodal) for Co-Speech Gesture Annotation
Updated with results 5/25/2025
Intro
Gemini 2.0-001 is a multimodal Google GenAI model that can be accessed for free (with no discernible processing limits encountered) from the Google AI Studio Google has recently created a few models with multimodal capabilities, including the chatbot Gemini-2.0 Flash, which is accessible through the studio directly, and Gemini 2.0-001, which was used for the automated testing. This blog post details how I created a very simple pipeline in Python in order to input videos taken from the Distributed Little Red Hen Lab’s 30_Videos dataset of the Ellen DeGeneres show and return a description of the actor’s movement and a co-speech gesture category. First, I did initial testing manually using Gemini-2.0 Flash in chat form in order to refine my prompt. Second, I wrote a series of Python scripts to automate the prompt/input/output process and record the data in a Microsoft Word Document (.docx). The goal of this testing was to assess Gemini’s ability to perform co-speech gesture analysis and categorization for videos with 1 actor 1 gesture.
Video Annotation
The videos used for this testing were 3-10s clips from the Ellen DeGeneres show, adapted from the 30_Videos dataset. Videos were cropped down from 3-7 minutes to shorter clips that contained 1 actor performing 1 gesture (or sequence of gestures). This dataset was originally intended for testing the capabilities of visual transformers ViViT and TubeViT, but it works fine as a test set for these purposes as well. Each new clip was renamed to reflect the original video name and the sequence from which it was taken. It was then colloquially labeled with the gesture within it, loosely in line with the ELAN annotations done by Peter Uhrig on the original 30_Videos dataset. The file names are not considered by Gemini when the analysis is being performed, so the presence of a label has not affected it’s output.
Example:
Original video: 11-11.mp4
Cropped video: 11-11-1_shrug.mp4
Manual Testing (Gemini 2.0 Flash)
Methods
To test Gemini’s capacity for labeling co-speech gesture on a small scale and refine my prompt before doing testing at scale, I started with Gemini 2.0 Flash through the Google AI Studio.
Prompts Tested:
“Can you classify the co-speech gesture in this video?”
“Using linguistic terminology, can you classify the co-speech gesture in this video?”
“Using linguistic terminology, can you describe the actor’s movement and then classify the co-speech gesture in this video?”
Final: “Using linguistic terminology, can you classify the co-speech gesture in this clip in two sections: 1) the action being performed, and 2) the co-speech gesture category the gesture belongs to?”
This final prompt returned two sections:
1) Action – a description of the actor’s movements in the video.
2) Classification – a 1-3 word category or set of categories for the gesture and a brief (~20 word) explanation of the movement/speech that led to the categorization.
I then tested 50 videos from the Ellen set to assess how the model would handle some of the more unique gestures in the set, including iconic gestures indicating path-source metaphors, thumbs up/down, PUOH gestures, and beats/baton. Gemini was able to handle 5 videos with the same prompt before an internal error occurred, so I tested the 50 videos in 5-video batches and recorded the output in an Xcel document with each part of the response marked “valid” or “invalid”. Since there’s no way for me to tell what sources Gemini is pulling it’s annotation terminology from, it’s annotations are sometimes different from the terminology the 30_Videos dataset is based on. As such, some “valid” results did not match my original annotations but are still linguistically correct. Gesture is fluid and how research discusses it is also somewhat varied.
Chat Results
Gemini 2.0 Flash was 97% successful at recognizing and describing the actor’s motion in the video and around 60% accurate at categorizing/describing the co-speech gesture present in the video.
Some interesting notes
- Gemini refused to categorize the gesture without also describing it and its linguistic significance. Attempts to get an output of 1-3 words describing a category were met with either a description with the key categories bolded or no output/internal error.
- While very accurate at identifying the action being mimicked in iconic gestures once an iconic was identified, Gemini liked to over-classify things as “Illustrators”, a broad category of gesture used primarily in communications science and pioneered by Dr. Paul Ekman. “They are used to provide emphasis, to make an action the speech is describing, to trace the flow of thought, to show spatial relationships, or to draw a picture in the air” (Ekman, 2021). The key words I’m hunting for are iconic, metaphoric, emblematic, deictic, and beat gestures.
API-Automated Testing (Gemini 2.0-001)
After performing the manual testing to ensure that Gemini could produce useable data, I wrote a script that automates this testing using the same prompt. It takes input in the form of .mp4 videos containing 1 actor performing 1 gesture and returns a word document with the video name, actions performed, gesture classification, video duration, and the processing duration. The project is posted on Github
Methods
When you’re using Google AI Studio, it auto-generates a script that when submitted to the API will simulate the chat, with context, that you’ve been having with the model. I used this script as a template, generated from my conversation with Gemini 2.0-Flash to base my own script off. This ensured that I would include all the bare necessities such as calling the API keys and using absolute file paths for the videos. I threw this in Cursor (an AI-assisted code editor) and built it out until it could process the videos and return valid responses, first in the command line and then saved in .docx format. The reason for using a .docx output instead of directly into a spreadsheet is that Gemini’s output for each section was around 10-30 words. For initial testing, I wanted to be able to manually assess the accuracy of the visual analysis, gesture category validity, and any subcategories it identified.
Because I was writing and testing the script at the same time as testing the outputs, coherency trials were conducted before the main run of 99 videos was completed. These coherency trials consisted of a run of the first 5 videos of the set until the script returned a correctly formatted result and the model output a coherent response. For the purposes of this explanation, coherent can be defined as a response that possesses all desired response sections, each containing a response of reasonable length. Both the prompt and the script were adjusted until this was achieved. Valid refers to a response that has returned a movement or gesture analysis that is technically correct. Correct refers to a response that matched the manual categorization I gave the gesture when doing my original annotations. A total of 6 coherency trials were conducted before a full test run was performed. The reason for the shorter coherency trials is twofold: 5 outputs is a manageable amount for me to verify, and Google API’s free tier sets a limit of requests one can make of each model each day. The limits for gemini-2.0-flash-001 are high enough that this type of testing is not prone to reaching them, but some of the other models tested have more restrictive limits, and keeping the protocol consistent is important.
Input: 99 .mp4 videos between 0.6 and 5.7 seconds (avg = 2.66s) containing one actor performing one gesture or set of gestures (usually multiple beats) as well as audio of what the actor said during the gesture(s).
Prompt: Please analyze the co-speech gesture in this video in two sections:
1) The action being performed (visual analysis)
2) The co-speech gesture category the gesture belongs to (beat, deictic, iconic, etc.)
Context: None
Once a full trial of 99 videos was conducted, manual validation was performed. In order to assess the model’s capacity for movement analysis and gesture recognition/subcategorization, the responses were compared to the manual annotation as well as the video itself.
Each response was tagged with:
The original file label (11-11-1.mp4)
It’s manual category (Man_Cat = emblem)
Whether the movement analysis was accurate (Movement = TRUE)
The category Gemini assigned (Category = emblem)
Whether this was valid (Cat_Val = TRUE)
The subcategory (Subcategory = shrug)
Whether the subcategory was valid (Sub_Val = TRUE)
Whether the explanation was valid (Explanation = TRUE)
Video duration (video_duration(s) =2.8)
Processing time (process_time(s) = 10.2)
Each of these 8 observations was manually assessed and recorded to create an .xcel file containing the results of the trial. This file was then uploaded to R to visualize some of the trends observed in the data. If I figure out how to get GitHub to support my blog having pictures, I will post them here. If not, they’re accessible on my GitHub[link] as a downloadable .pdf file.
API Results
Gemini 2.0 flash 001 was 88% successful at returning valid movement analysis and 83.8% successful returning a valid gesture categorization.
Validity of Response by Manual Category overall 83.8%
Beat/deictic 100% of 1
Deictic 100% of 4
Emblem 100% of 1
Beat 87.8% of 41
Iconic/beat 87.5% of 8
Metaphoric 81.8% of 11
Iconic 80.8% of 26
Regulator 57.1% of 7
Validity of Subcategories
Beat 94.1% of 17
Iconic 78.9% of 19
Metaphoric 62.5% of 8
Correct (matching manual category) overall 42.4%
Beat/deictic 0% of 1
Deictic 100% of 4
Emblem 100% of 1
Beat 48.8% of 41
Iconic/beat 12.5% of 8
Metaphoric 63.6% of 11
Iconic 30.8% of 26
Regulator 57.1% of 7
Total input: 4.38 minutes
Total processing time: 13.1 minutes
Average processing time per video: 7.96s
Manual Data Validation Format
 Table 1: first 5 observations of 11 datapoints (adapted from the Xcel file).
Table 1: first 5 observations of 11 datapoints (adapted from the Xcel file).
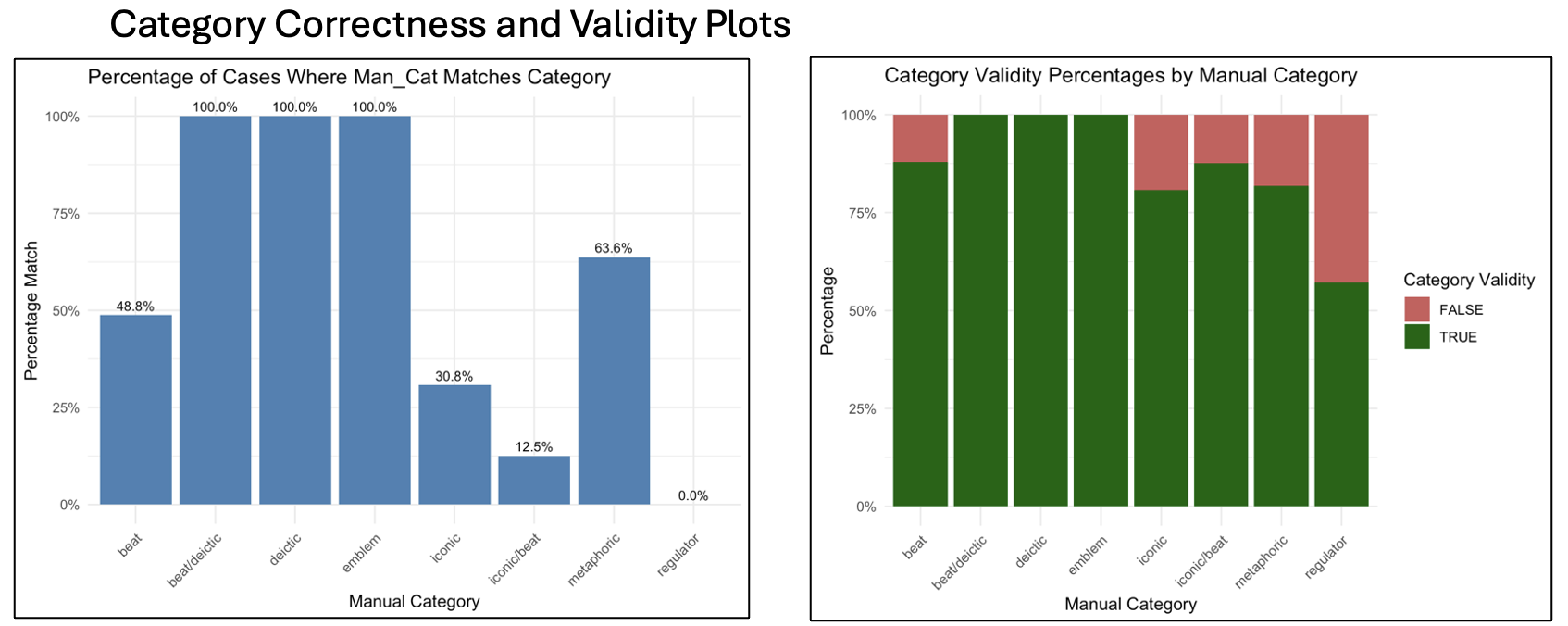 Figure 1 (Left): Percentage of Cases where the manually annotated category matches the category that Gemini assigned. Figure 2 (Right): Visual representation of the ratio of valid/invalid categorizations Gemini made, organized by manual category.
Figure 1 (Left): Percentage of Cases where the manually annotated category matches the category that Gemini assigned. Figure 2 (Right): Visual representation of the ratio of valid/invalid categorizations Gemini made, organized by manual category.
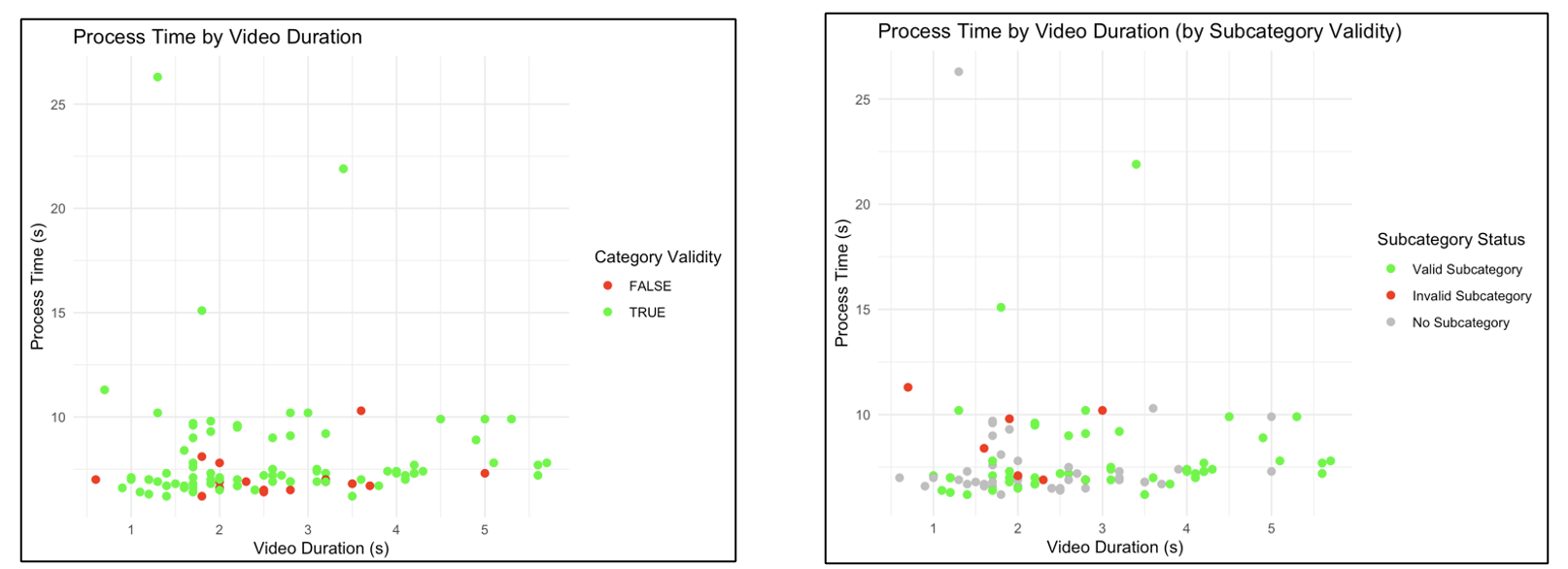 Figure 3 (Left): Processing time over video duration. Videos that Gemini returned valid gesture categories for are represented by green points, videos that Gemini returned invalid gesture categories for are represented by red points. Figure 4 (Right): Processing time over video duration. Videos that Gemini returned valid gesture subcategories for (E.g. correct identification of the subject of an iconic gesture) are represented with green points. Videos that Gemini returned invalid subcategories for are represented by red points. Videos that Gemini returned no subcategory for are represented by grey points.
Figure 3 (Left): Processing time over video duration. Videos that Gemini returned valid gesture categories for are represented by green points, videos that Gemini returned invalid gesture categories for are represented by red points. Figure 4 (Right): Processing time over video duration. Videos that Gemini returned valid gesture subcategories for (E.g. correct identification of the subject of an iconic gesture) are represented with green points. Videos that Gemini returned invalid subcategories for are represented by red points. Videos that Gemini returned no subcategory for are represented by grey points.
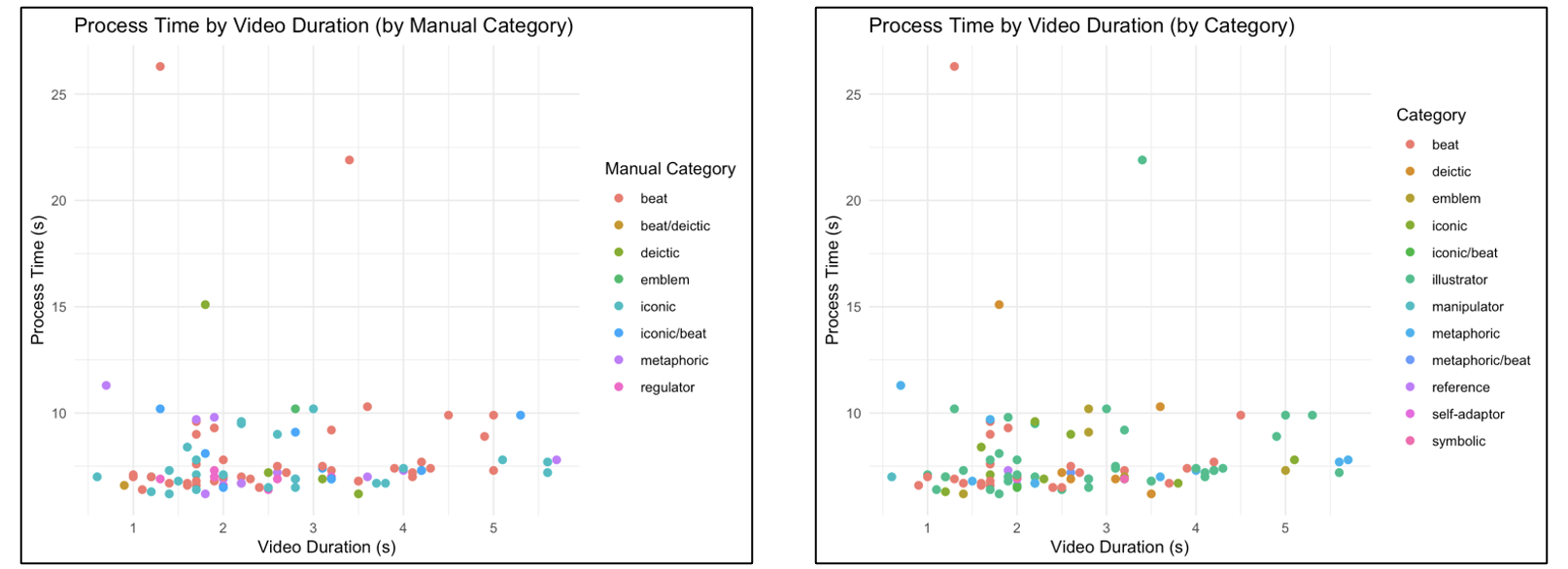 Figure 5 (Left): Processing time over video duration, with each manual gesture category labeled with a unique color. Figure 6 (Right): Process time over video duration, with each Gemini-assigned category labeled with a unique color.
Figure 5 (Left): Processing time over video duration, with each manual gesture category labeled with a unique color. Figure 6 (Right): Process time over video duration, with each Gemini-assigned category labeled with a unique color.
If the images are not loading in your browser, the data visualization for these results can be accessed here
Discussion
The reason that the percentage for “validity” is so much higher than “correctness” is because there is no context for the model in these trials. The original annotations were specifically based on the work of Janna Bressen, Kendon (1980) and McNeill (1992). There’s no way to tell exactly what Gemini was trained on in the realm of co-speech gesture. It classified many beat, iconic, and metaphoric gestures as “Illustrators”, a term popularized by Dr. Paul Ekman for usage in psychological study. Unfortunately, what Dr. Ekman cared about is vastly different than what is salient for co-speech gesture analysis, so things classified primarily as “Illustrators” and then sub-categorized as something useful is not desirable. Further trials with context (likely a PDF of linguistic co-speech gesture taxonomy) will be conducted in future work.
Unfortunately, Gemini 2.0 is not able to timestamp gesture onset. This is not terrible in videos that have already been cropped to only contain one actor performing one gesture, but would be a nice capability to have in order to analyze longer videos with multiple actors and or gestures. 17% invalidity is high, and so this pipeline cannot currently be used to fully autonomously annotate gesture. Manual checking is still required. However, some categories had very high validity, up to 100%, while others had very low. In instances where the system has correctly identified 100% of a certain category of gestures, less manual checking is required, and a researcher could reasonably spend most of their time checking the categories of gesture that have high fail rates. In this sense, using an automated annotator would still save time in increase the size dataset that can be created.
While the average processing time was 7.9s, this includes two outliers at 26.3s and 21.9s. Removing these two outliers, the average processing time is 7.62s. Interestingly, both outliers were beats with valid classification. I was curious as to whether processing time was correlated with video length or validity, so I plotted video duration by processing time in R and then colored the points based on validity of category (Figure 1), subcategory (Figure 2), and match correctness between Man_Cat and Category (Figure 3). I did not find any significant correlations, but they are interesting visuals as to the shakedown of the data points.
Conclusion
Gemini 2.0 Flash 001 has shown significant movement analysis capabilities (88% accuracy) and promising gesture recognition (83.8% validity, 42.4% correct match). Due to its high error rate for gesture classification and usage of undesirable classification labels such as Illustrator, further work is required before it can be incorporated into unsupervised dataset pre-processing. In its current state, it may be useful to generate movement descriptions that can be used to interpret gestures and recognize whether a gesture is present, which are both useful to researchers out of the box. Further testing with prompt variation and context is required to determine whether it can annotate gestures linguistically fully unsupervised with the correct parameters.
Example Output:
Video: 11-11-1_shrug.mp4 (Duration: 2.8 seconds)
Analysis:
Action Performed:
Here’s a breakdown of the co-speech gesture in the clip:
Action: The person in the clip extends both of their arms outwards with their palms facing upwards.
Co-Speech Gesture Category:
2.Co-speech Gesture Category: The gesture can be classified as an illustrator, specifically a beat and deictic gesture. It seems to emphasize and amplify what the person is saying.
Raw Response for Reference:
Here’s a breakdown of the co-speech gesture in the clip:
- Action: The person in the clip extends both of their arms outwards with their palms facing upwards.
- Co-speech Gesture Category: The gesture can be classified as an illustrator, specifically a beat and deictic gesture. It seems to emphasize and amplify what the person is saying.
Processing Time:
Total time: 6.9 seconds
Acknowledgements:
Thank you to Dr. Peter Uhrig of the Max Planck Institute of Psycholinguistics for creating this dataset and letting me use it.
To Google AI for making Gemini free to use for researchers.
And to the Cursor team for making my life a lot easier.
References:
Medium Article on Dr. Paul Ekman’s Gesture Classification
Bressen, Jana. (2016). Overview of Notation Conventions For Notation of Form In Gestures. Retrieved November 4, 2024.
Kendon, A. (1980). Gesticulation and speech: Two aspects of the process of utterance. In M. R. Key (Ed.), The Relationship of Verbal and Nonverbal Communication (pp. 207-228). Berlin: De Gruyter.
McNeill, D. (1992). Hand and Mind: What Gestures Reveal About Thought. University of Chicago Press.
Steen, F. F., Hougaard, A., Joo, J., Olza, I., Cánovas, C. P., Pleshakova, A., Ray, S., Uhrig, P., Valenzuela, J., Woźny, J., & Turner, M. (2018). Toward an infrastructure for data-driven multimodal communication research. Linguistics Vanguard, 4(1).
Turchyn, S., Olza Moreno, I., Pagán Cánovas, C., Steen, F., Turner, M., Valenzuela, J., & Ray, S. (2018). Gesture Annotation With a Visual Search Engine for Multimodal Communication Research. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1).
Turner, M. B., & Steen, F. F. (2012). Multimodal Construction Grammar. SSRN Electronic Journal.
Steps to use my API Script to analyze co-speech gesture.
1) Go to my GitHub for the project
2) Fork the whole thing to your own repository/download so you can adapt it to your own OS (Mine was tested and run through MacOS Command line)
3) Make Gemini API Keys
4) Read the ReadMe file and follow its instructions. This will mostly involve changing out “/file/path/to/video” and “/file/path/to/output” to the actual filepaths you want Gemini to pull videos from and write output. You also have to set your API Key as an environment variable. I highly recommend setting up a virtual environment .venv
to run it in because it will not work if you have multiple Python interpreters running or the requirements have conflicts in the python environment.
Steps I used to make this API Script Gemini 2.0-001
1) Went to the Gemini API and generate API keys. One set of keys can be used for any model you select.
2) Did some prompt testing to verify that the prompt included in your API script will return the type of data I was looking for.
I think I went through 5-6 iterations of my prompt before landing on one I liked.
“Can you classify the co-speech gesture in this video?”
“Using linguistic terminology, can you classify the co-speech gesture in this video?”
“Using linguistic terminology, can you describe the actor’s movement and then classify the co-speech gesture in this video?”
(final) “Using linguistic terminology, can you classify the co-speech gesture in this clip in two sections: 1) the action being performed, and 2) the co-speech gesture category the gesture belongs to?”
3) Put together my API script. Gemini speaks python, so if you know how to write Python, you’re in luck. If not, Gemini can probably also help you write one. I used Cursor, which is an AI-assisted code. editor to make this script, writing the bare minimum and then asking it to fill in functionality like formatting the data into a .docx and adding some extra data captures to it like processing time.
5) De-bugged the script so that it worked. Cursor is great at writing scripts, but terrible at keeping track of what packages are running in the environment, what dependencies
those packages have, etc. I wrote a requirements.txt document and a ReadMe so that I (and anyone replicating my code) could have an easier time setting it up.
6) Uploaded my work to GitHub including a ReadMe, requirements.txt, and a .gitignore if necessary. Cursor can help you write these if you don’t know how… But
I had to check that it actually included everything. Cursor is still an AI agent and while it is very useful, it does hallucinate, lack memory of its past actions and edits, and leave things out occasionally.